前言
在iOS的日常编码中,GCD很好地隔离了我们与线程(pthread)之间的直接交流,跟我们打交道的只有队列和Block,时间久了甚至感觉不到线程的存在。一直想找机会好好研究一下GCD底层,领略下其博大精深之要义.经过初期调研发现:GCD源码分析资料稀少,且比较零散,很难全面地对GCD进行了解,原因可能是这方面的业务需求驱动不是特别强烈,现有GCD的API足够解决所有的业务需求。但是这仍然阻止不了我对GCD底层原理了解的一腔热血,冲动之下决定给自己挖个坑,写一个GCD源码分析系列,阐述下自己对GCD底层原理的了解和理解。
GCD版本选择
接下来就是选择要分析的GCD源码版本,纵向对比了下,发现越到后期的版本,工程越庞大,文件数激增,并且源码风格越来越不友好,里面充斥了大量的宏编译选项,阅读起来很费神,这对了解底层机制十分不利。通过各个版本对比之下,最终选定了版本 libdispatch-84.5.5。
这就是这个版本的所有工程文件!但是麻雀虽小,五脏俱全,它仍然包含了所有的GCD的所有内容。
前期准备
在阅读GCD源码之前,需要对一些相关的基础知识做下了解
原子操作
在分析源码之前,先来了解一些关于原子操作的代码,不需要记住,只需要有个印象,回头查询1
2
3
4
5
6
7
8
__sync_lock_test_and_set((p), (n))将*p设为value并返回*p操作之前的值。__sync_bool_compare_and_swap((p), (o), (n))这两个函数提供原子的比较和交换:如果*p == o,就将n写入*p(p代表地址,o代表oldValue,n代表newValue)__sync_add_and_fetch((p), 1)先自加1,再返回__sync_sub_and_fetch((p), 1)先自减1,再返回__sync_add_and_fetch((p), (v))先自加v,再返回__sync_sub_and_fetch((p), (v))先自减v,再返回__sync_fetch_and_or((p), (v))先返回,再进行或运算__sync_fetch_and_and((p), (v))先返回,再进行与运算
__builtin_expect
1 | long __builtin_expect (long EXP, long C) |
处理器一般采用流水线模式,有些里面有多个逻辑运算单元,系统可以提前取多条指令进行并行处理,但遇到跳转时,则需要重新取指令,这相对于不用重新去指令就降低了速度。然而由于程序员在分支预测方面做得很糟糕,所以用这个内建函数__builtin_expect来帮助程序员处理分支预测,优化程序。其第一个参数EXP为一个整型表达式,这个内建函数的返回值也是这个EXP,而C为一个编译期常量,这个函数的语义是:我期望EXP表达式的值等于常量C,编译器应当根据我提供的期望值进行优化。例如:1
2
3
4if (__builtin_expect(x, 0))
return 1;
else
return 2;
很明显,x的期望值为0,也就是x有很大的概率为0,所以走if分支的可能性较小,所以编译器会这样编译:1
2
3
4if (!x)
return 2;
else
return 1;
这样,每次CPU都能大概率地执行到预取的编译后的if分支,从而提高了分支预测的准确性,进而提升了CPU指令的执行速度。
fastpath && slowpath
1 |
有了__builtin_expect基础,苹果引入的fastpath和slowpath这两个宏就不难理解了:
- fastpath 表示该条件多数情况下会发生。
- slowpath 表示你可以确认该条件是极少发生的。
DISPATCH_DECL
1 |
GCD源码中很多地方都可以看到这个宏,举个栗子:1
DISPATCH_DECL(dispatch_queue);
宏展开为:1
typedef struct dispatch_queue_s *dispatch_queue_t
dispatch_queue_t就可以用来定义一个dispatch_queue_s结构体的指针。
基本数据结构
dispatch_object_t
1 | typedef union { |
可以看出,dispatch_object_t是一个联合体,所以当用dispatch_object_t 可以代表这个联合体内的所有数据类型。
注意__attribute__((transparent_union))是一种典型的 透明联合体,
透明联合类型削弱了C语言的类型检测机制。起到了类似强制类型转换的效果,通过透明联合体,使得dispatch_object_s就像C++中的基类,在函数参数类型的转换上,给C语言的参数传递带来极大的方便。
考虑到在底层,类型实质上是不存在的,因此所谓的透明联合类型,也就是在一定程度上打破了类型对我们的束缚,使数据以一种更底层的角度呈现在我们面前。不过这样也弱化了C语言对类型的检测,由此也可能带来一些很严重的错误。
dispatch_object_s
1 | struct dispatch_object_s { |
dispatch_object_s结构体是整个GCD的基类,地位十分重要,里面的一些成员已经在注释中做了基本的解释,随着剖析的逐步深入,我们会逐步了解这些成员存在的意义。
可以看出 do_vtable 的类型是dispatch_object_vtable_s:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18struct dispatch_object_vtable_s {
DISPATCH_VTABLE_HEADER(dispatch_object_s);
};
unsigned long const do_type; \ // 数据的具体类型
const char *const do_kind; \ // 数据的类型描述字符串
size_t (*const do_debug)(struct x *, char *, size_t); \ // 用来获取调试时需要的变量信息
struct dispatch_queue_s *(*const do_invoke)(struct x *);\ // 唤醒队列的方法,全局队列和主队列此项为NULL
bool (*const do_probe)(struct x *); \ // 用于检测传入对象中的一些值是否满足条件
void (*const do_dispose)(struct x *) // 销毁队列的方法,通常内部会调用 这个对象的 finalizer 函数
这个结构体内包含了这个dispatch_object_s 的操作函数,而且针对这些操作函数,定义了相对简短的宏,方便调用
dispatch_continuation_s
该结构体主要用来封装block和function1
2
3
4
5
6
7
8
9
10
11struct dispatch_continuation_s {
DISPATCH_CONTINUATION_HEADER(dispatch_continuation_s);
dispatch_group_t dc_group;
void * dc_data[3];
};
const void * do_vtable; \
struct x *volatile do_next; \
dispatch_function_t dc_func; \
void * dc_ctxt
dispatch_continuation_s 代表任务类型,通常 dispatch_async内的block最终都会封装成这个数据类型
If dc_vtable is less than 127, then the object is a continuation.
Otherwise, the object has a private layout and memory management rules. The
first two words must align with normal objects.
dispatch_queue_s
1 |
|
可以看出,dispatch_queue_s 和 dispatch_object_s 差别在于 dispatch_queue_s 多了DISPATCH_QUEUE_HEADER 和 dq_label[DISPATCH_QUEUE_MIN_LABEL_SIZE],我们从中也可以看出,我们队列起名要少于64个字符
dispatch_group_s
1 | DISPATCH_DECL(dispatch_group); |
可以看出,dispatch_group_t 等效于 dispatch_group_s*,那么dispatch_group_s究竟本质是什么呢?当我去找dispatch_group_s的定义时,无论如何也找不到,终究还是不能获悉dispatch_group_s的真正结构,看来只有另辟蹊径。
在看源码的过程中,在semaphore.c文件中的dispatch_group_create函数定义中发现了一些端倪1
2
3
4
5dispatch_group_t
dispatch_group_create(void)
{
return (dispatch_group_t)dispatch_semaphore_create(LONG_MAX);
}
结果令人十分诧异:dispatch_group_t本质上竟然是一个value为LONG_MAX的semaphore !!!
dispatch_source_s
1 | struct dispatch_source_s { |
dispatch_semaphore_s
1 | struct dispatch_semaphore_s { |
UML图
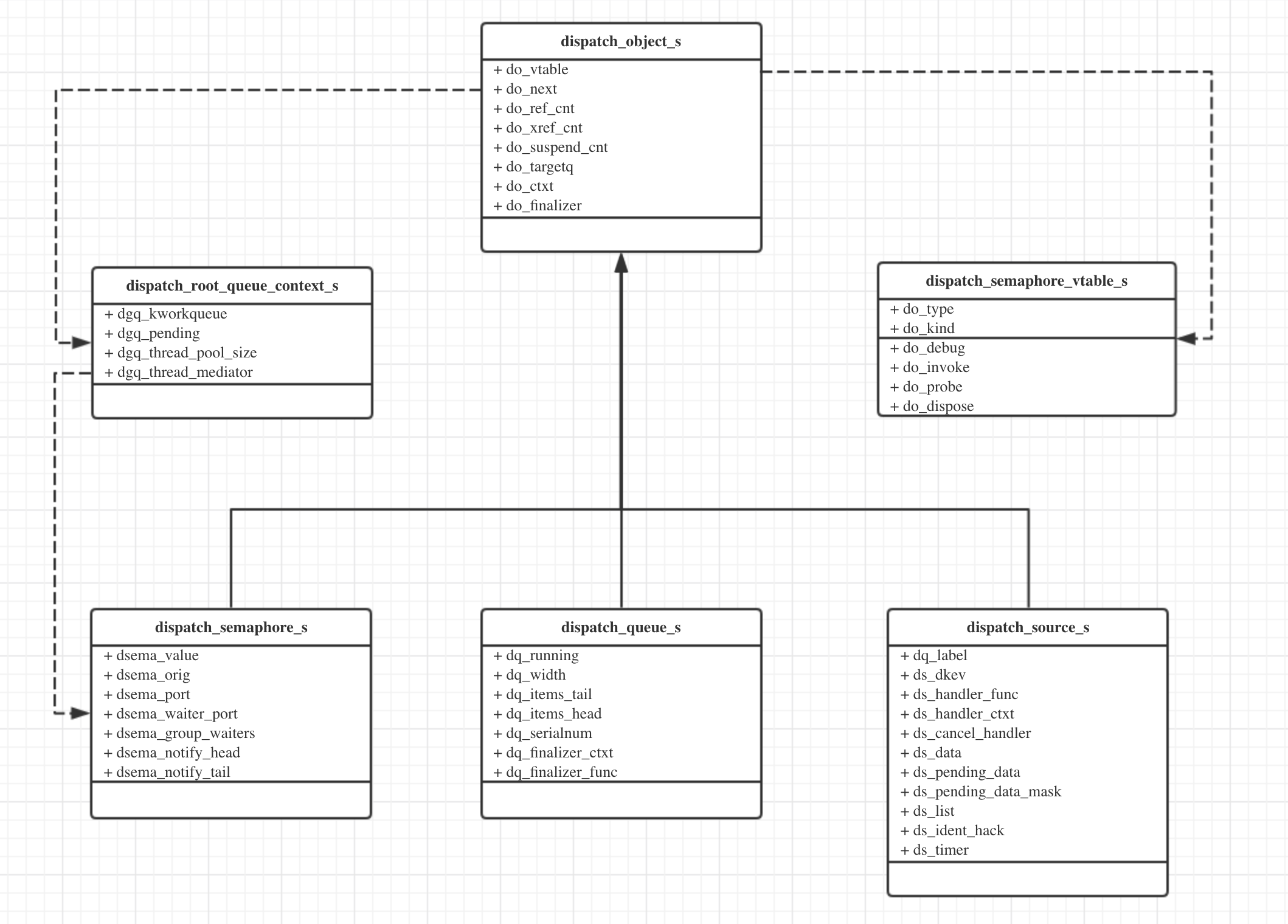
libdispatch初始化
1 | void libdispatch_init(void) |
pthread_key_t
在多线程环境下,由于数据空间是共享的,因此全局变量也为所有线程所共有。但有时应用程序设计中有必要提供线程私有的全局变量,仅在某个线程中有效,但却可以跨多个函数访问,比如程序可能需要每个线程维护一个链表,而使用相同的函数操作,最简单的办法就是使用同名而不同变量地址的线程相关数据结构,这样的数据结构称为 线程私有数据(Thread-specific Data,或TSD)。
GCD一共定义了4个key:1
2
3
4static const unsigned long dispatch_queue_key = __PTK_LIBDISPATCH_KEY0;
static const unsigned long dispatch_sema4_key = __PTK_LIBDISPATCH_KEY1;
static const unsigned long dispatch_cache_key = __PTK_LIBDISPATCH_KEY2;
static const unsigned long dispatch_bcounter_key = __PTK_LIBDISPATCH_KEY3;
pthread_key_create
_dispatch_thread_key_init_np调用pthread_key_create1
int pthread_key_create(pthread_key_t *key, void (*destr_function) (void *))
该函数从TSD池中分配一项,将其值赋给key供以后访问使用。如果destr_function不为空,在线程退出(pthread_exit())时将以key所关联的数据为参数调用destr_function(),以释放分配的缓冲区。
不论哪个线程调用pthread_key_create(),所创建的key都是所有线程可访问的,但各个线程可根据自己的需要往key中填入不同的值,这些值特定于线程并且针对每个线程单独维护。这就相当于提供了一个同名而不同值的全局变量。
pthread_setspecific & pthread_getspecific
这里主线程将自己的TSD设置为_dispatch_main_q函数的地址1
_dispatch_thread_setspecific(dispatch_queue_key, &_dispatch_main_q);
总结
本文涉及到的基本数据结构只是为了跟大家混个脸熟,实际上为了讲数据结构而讲数据结构,也并非能讲清楚,在后续的GCD源码分析系列中将会逐步阐明。

